introdunction to SIMD programming
Unite 2015 Tokyo の講演で詳細を話せなかったのが心残りだったので、大量のオブジェクトの更新処理についてこの場で書いてみます。
主に C++ で、簡単なパーティクルエンジンを作り、それを SIMD を用いて高速化する手順を解説します。
話を簡単にするため、以下の前提を設けます。
・x86 環境のみ考慮
・パーティクルは位置と速度のみを保持
・パーティクル同士の相互衝突は総当たりで計算
総当たりなので超遅いですが、実装は容易で SIMD による恩恵を受けやすく、題材として手頃です。
この記事の中で引用されているソースの元は こちら、ビルド結果 (上のスクリーンショットのデモプログラム) は こちら になります。
相互衝突するパーティクルを実装する場合、お互いの距離を計算し、当たっていたらめり込み具合に応じて押し返す、というのがよくある実装だと思います。まずはそれをストレートに C++ で実装してみます。
const int m_particle_count = 4096; Particle m_particles[m_particle_count]; float m_particle_size = 0.1f; float m_pressure_stiffness = 500.0f; // 押し返し係数 float dt = 1.0f / 60.0f; // 速度を更新。パーティクル同士の押し返し for (int i = 0; i < m_particle_count; ++i) { float3 &pos1 = m_particles[i].position; float3 accel = { 0.0f, 0.0f, 0.0f }; for (int j = 0; j < m_particle_count; ++j) { float3 &pos2 = m_particles[j].position; float3 diff = pos2 - pos1; float dist = length(diff); if (dist > 0.0f) { // dist==0.0 : 自分自身との衝突なので省略 float3 dir = diff / dist; // めり込んでいたら反対方向に加速度を追加 float overlap = std::min<float>(0.0f, dist - m_particle_size*2.0f); float3 a = dir * (overlap * m_pressure_stiffness); accel = accel + a; } } float3 &vel = m_particles[i].velocity; vel = vel + accel * dt; } // 位置を更新。マルチスレッド対応を考慮して速度更新とは分ける for (int i = 0; i < m_particle_count; ++i) { float3 &pos = m_particles[i].position; float3 &vel = m_particles[i].velocity; pos = pos + (vel * dt); }
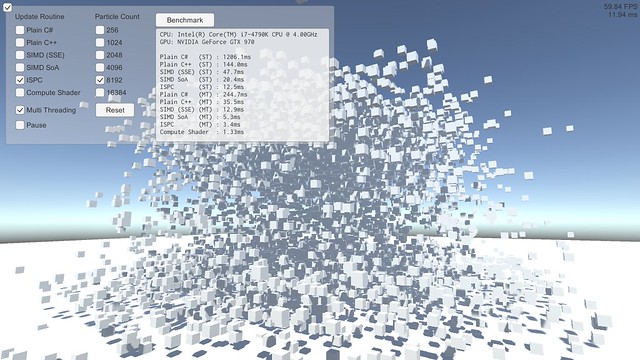
最適化を有効にしてビルドし、とりあえずシングルスレッドで 4096 個のパーティクルを相互に衝突させてみたところ、所要時間は以下のようになりました。
Plain C++ (ST) : 140.0ms
これがスタートラインです。これをがんばって速くしていきます。
ついでに、適当に重力加速と床とのバウンド処理も入れて Unity で可視化してみるとこうなりました。単純実装ながらなかなかいい感じではないでしょうか。

SIMD
近年では大抵の CPU には 1 命令で複数のデータを同時に計算する命令群が備わっています。これを使うと、例えば 4 つの float の足し算や掛け算を一度に行うことができます。これらは SIMD (Single Instruction Multiple Data) と呼ばれ、CPU プログラミングでシビアに速度を求める場合避けては通れない道になります。
x86 系 CPU には SSE という SIMD 命令群が備わっており、今回の例ではこれを用います。(x86 用なので ARM など他の CPU では動きません。ARM の CPU も大抵は NEON という SIMD 命令群が備わっており、マルチプラットフォーム対応するには個別に実装するなりライブラリを用いるなりする必要があります)
SSE の命令群は intrinsic と呼ばれる関数を用いることで C++ から使うことができます。最初のストレートな C++ 実装を、ベクトル演算を SSE の命令で置き換える形で書きなおすと以下のようになります。
__m128 particle_size2 = _mm_set_ps1(m_particle_size*2.0f); __m128 pressure_stiffness = _mm_set_ps1(m_pressure_stiffness); __m128 dt = _mm_set_ps1(dt_); __m128 zero = _mm_setzero_ps(); // パーティクル同士の押し返し for (int i = 0; i < m_particle_count; ++i) { __m128 pos1 = _mm_load_ps((float*)&m_particles[i].position); __m128 accel = zero; for (int j = 0; j < m_particle_count; ++j) { __m128 pos2 = _mm_load_ps((float*)&m_particles[j].position); __m128 diff = _mm_sub_ps(pos2, pos1); __m128 dist = length(diff); __m128 dir = _mm_div_ps(diff, dist); __m128 overlap = _mm_min_ps(zero, _mm_mul_ps(_mm_sub_ps(dist, particle_size2), pressure_stiffness)); __m128 a = _mm_mul_ps(dir, overlap); accel = _mm_add_ps(accel, select(zero, a, _mm_cmpgt_ps(dist, zero))); } __m128 vel = _mm_load_ps((float*)&m_particles[i].velocity); vel = _mm_add_ps(vel, _mm_mul_ps(accel, dt)); _mm_store_ps((float*)&m_particles[i].velocity, vel); } // 位置を更新 for (int i = 0; i < m_particle_count; ++i) { __m128 pos = _mm_load_ps(m_particles[i].position.v); __m128 vel = _mm_load_ps(m_particles[i].velocity.v); pos = _mm_add_ps(pos, _mm_mul_ps(vel, dt)); _mm_store_ps(m_particles[i].position.v, pos); }
__m128 というのが SSE 用のデータ型で、float が 4 つ格納できる 16 byte のデータになっています。
_mm で始まる関数群が SSE の intrinsic で、大体はこの intrinsic が SSE の命令に直接対応するようになっています。アンダースコアまみれで見にくいですが、関数名に mul とか add とかついているので初見の方でも大体何やってるのかわかるんじゃないかと思います。
注意が必要な点がいくつかあります。
_mm_load_ps() はメモリから SSE のレジスタにデータを移す命令ですが、ロード先のアドレスは 16 byte にアラインされている必要があります。されていない場合クラッシュします。アライン不要の _mm_loadu_ps() というのもありますが、若干速度にペナルティがあるので今回は使っていません。これらは SSE のレジスタからメモリにデータを移す _mm_store_ps() にも同じことが言えます。このため、今回の Particle は position も velocity も 4 次元ベクトル (というか x,y,z + パディング) としています。
SIMD プログラミングでは、例えば x+y+z みたいなベクトルの水平方向の計算をする場合ややこしいことをやる必要があります。こういう処理の典型的な例が内積です。3 次元の内積のストレートな C++ 実装はこうですが、
inline float dot(float3 v1, float3 v2) { return v1.x*v2.x + v1.y*v2.y + v1.z*v2.z; }
SSE だとこうなります。
inline __m128 dot(__m128 v1, __m128 v2) { __m128 d = _mm_mul_ps(v1, v2); // d: x,y,z,w __m128 t = _mm_shuffle_ps(d, d, _MM_SHUFFLE(2, 1, 2, 1)); // t: z,y,z,y d = _mm_add_ss(d, t); // d: xz,... t = _mm_shuffle_ps(t, t, _MM_SHUFFLE(1, 1, 1, 1)); // t: y,y,y,y d = _mm_add_ss(d, t); // d: xyz,... return _mm_shuffle_ps(d, d, _MM_SHUFFLE(0, 0, 0, 0)); // xyz,xyz,xyz,xyz } // 上の SSE 化したパーティクルコードの length() inline __m128 length(__m128 v) { return _mm_sqrt_ps(dot(v,v)); }
_mm_shuffle_ps() が要素を交換する命令で、これを使って要素を入れ替えつつ足しあわせています。見ての通り実装がめんどくさい上に並列性も少なく、コストの高い処理になります。これは SSE に限らず SIMD プログラミングではつきまとう問題で、できるだけ避けた方がいいですが必要な状況も多いです。(SSE 3 で水平方向計算の命令が追加され、SSE 4 では内積を計算するそのものズバリな命令までありますが、今回は一応一般的な SIMD プログラミングという体裁なので使いません)
あとは分岐。SIMD の場合、分岐は両パス計算して結果を選択した方がずっと速いケースが多いです。比較命令 (_mm_cmpgt_ps() = compare greater than など) は結果が真の要素は全ビットが立っている (0xffffffff) ので、これを使ってビット演算で結果を選択します。
inline __m128 select(__m128 v1, __m128 v2, __m128 mask) { __m128 t1 = _mm_andnot_ps(mask, v1); __m128 t2 = _mm_and_ps(v2, mask); return _mm_or_ps(t1, t2); }
例えば v1 が {0,1,2,3}、v2 が {4,5,6,7} で mask が {0, 0xffffffff, 0xffffffff, 0} の場合、この select() は {0,5,6,3} を返します。上の SSE 化したパーティクルのコードもこれで結果を選択しています。
SSE 化したソースをビルドして最初のケースと同条件 4096 パーティクル シングルスレッドで動かしてみました。
Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms (new!)
実に 3 倍も速くなりました。
SoA
SIMD 化により大きく速くはなりましたが、上記の SSE 化したコードには色々無駄があります。position も velocity も実際には x,y,z の 3 要素しか使われていません。なので SIMD 演算の際 w 要素部分の計算は完全に無駄になっており、計算リソースを 25% も無駄にしていることになります。また、先述の dot() / length() の中の並べ替えも大きなロスになります。
これらを解決する手法として、SoA (Structure of Arrays) と呼ばれるデータ構造があります。
C++ で多数のオブジェクトを扱う場合、各オブジェクトに付随するデータを class や struct にまとめて配列にする、というのが一般的だと思われます。
struct Particle { float pos_x, pos_y, pos_z; float vel_x, vel_y, vel_z; }; Particle particles[particle_count];
このようなデータの持ち方は AoS (Array of Structures) と呼ばれることもあります。SoA はこれとは逆で、データの各要素を配列にする、というデータの持ち方になります。
float pos_x[particle_count]; float pos_y[particle_count]; float pos_z[particle_count]; float vel_x[particle_count]; float vel_y[particle_count]; float vel_z[particle_count];
直感的ではないデータの持ち方ですが、SIMD プログラミングではこれは大きなメリットがあります。4 つのオブジェクトを同時に計算できるようになるのです。先ほどの続きで、内積を例に考えてみましょう。SoA なデータに対して SSE で内積と距離を計算する場合、こうなります。
inline __m128 soa_dot(__m128 x1, __m128 y1, __m128 z1, __m128 x2, __m128 y2, __m128 z2) { __m128 tx = _mm_mul_ps(x1, x2); __m128 ty = _mm_mul_ps(y1, y2); __m128 tz = _mm_mul_ps(z1, z2); return _mm_add_ps(_mm_add_ps(tx, ty), tz); } inline __m128 soa_length(__m128 x, __m128 y, __m128 z) { return _mm_sqrt_ps(soa_dot(x,y,z, x,y,z)); }
やってることはストレートな C++ 実装と同じですが、4 つのベクトルを同時に計算するようになっています。前述のベタな SSE 化の dot() と違い、shuffle は必要ないですし w 要素の計算が無駄になることもありません。ベタな SSE 化はベクトル演算それぞれを SSE 命令に置き換えていましたが、SoA の場合 4 つのパーティクルを同時に行うことで並列化するイメージです。
SoA にはスケーラビリティの面でも大きなメリットがあります。近年の x86 CPU には AVX という SIMD 命令群が追加されており、これを使うと 8 つの float を同時に計算できます。しかし 8 次元ベクトルなんてゲーム開発ではまず出てこないので、単純にベクトル演算を SIMD 命令に置き換えるアプローチではこれを活かすのは難しいです。一方、SoA であれば 8 オブジェクト並列に計算することで最大限に恩恵を受けることができますし、将来 16 並列や 32 並列 SIMD が出てきたとしても簡単に対応できます。
実際にパーティクルを SoA 化して計算してみます。まずパーティクルデータを SoA 化する必要があります。AoS <-> SoA の転置を行うには、SSE では以下のような処理を行います。
union soafloat4 { struct { __m128 x, y, z, w; }; __m128 v[4]; }; inline soafloat4 soa_transpose(__m128 v0, __m128 v1, __m128 v2, __m128 v3) { __m128 r1 = _mm_unpacklo_ps(v0, v1); __m128 r2 = _mm_unpacklo_ps(v2, v3); __m128 r3 = _mm_unpackhi_ps(v0, v1); __m128 r4 = _mm_unpackhi_ps(v2, v3); soafloat4 r = { _mm_shuffle_ps(r1, r2, _MM_SHUFFLE(1, 0, 1, 0)), // {v0.x, v1.x, v2.x, v3.x} _mm_shuffle_ps(r1, r2, _MM_SHUFFLE(3, 2, 3, 2)), // {v0.y, v1.y, v2.y, v3.y} _mm_shuffle_ps(r3, r4, _MM_SHUFFLE(1, 0, 1, 0)), // {v0.z, v1.z, v2.z, v3.z} _mm_shuffle_ps(r3, r4, _MM_SHUFFLE(3, 2, 3, 2)) };// {v0.w, v1.w, v2.w, v3.w} return r; }
これを用いてパーティクルを SoA 化し、衝突計算を行います。
__m128 particle_size2 = _mm_set_ps1(m_particle_size*2.0f); __m128 pressure_stiffness = _mm_set_ps1(m_pressure_stiffness); __m128 dt = _mm_set_ps1(dt_); __m128 zero = _mm_setzero_ps(); // パーティクル同士の押し返し for (int i = 0; i < m_particle_count; ++i) { __m128 pos1x = _mm_set_ps1(m_soa.pos_x[i]); __m128 pos1y = _mm_set_ps1(m_soa.pos_y[i]); __m128 pos1z = _mm_set_ps1(m_soa.pos_z[i]); __m128 accelx = zero; __m128 accely = zero; __m128 accelz = zero; for (int j = 0; j < m_particle_count; j += 4) { __m128 pos2x = _mm_load_ps(&m_soa.pos_x[j]); __m128 pos2y = _mm_load_ps(&m_soa.pos_y[j]); __m128 pos2z = _mm_load_ps(&m_soa.pos_z[j]); __m128 diffx = _mm_sub_ps(pos2x, pos1x); __m128 diffy = _mm_sub_ps(pos2y, pos1y); __m128 diffz = _mm_sub_ps(pos2z, pos1z); __m128 dist = soa_length(diffx, diffy, diffz); __m128 dirx = _mm_div_ps(diffx, dist); __m128 diry = _mm_div_ps(diffy, dist); __m128 dirz = _mm_div_ps(diffz, dist); __m128 overlap = _mm_min_ps(zero, _mm_mul_ps(_mm_sub_ps(dist, particle_size2), pressure_stiffness)); __m128 ax = _mm_mul_ps(dirx, overlap); __m128 ay = _mm_mul_ps(diry, overlap); __m128 az = _mm_mul_ps(dirz, overlap); __m128 gt = _mm_cmpgt_ps(dist, zero); accelx = _mm_add_ps(accelx, select(zero, ax, gt)); accely = _mm_add_ps(accely, select(zero, ay, gt)); accelz = _mm_add_ps(accelz, select(zero, az, gt)); } __m128 velx = _mm_set_ss(m_soa.vel_x[i]); __m128 vely = _mm_set_ss(m_soa.vel_y[i]); __m128 velz = _mm_set_ss(m_soa.vel_z[i]); velx = _mm_add_ss(velx, _mm_mul_ss(reduce_add(accelx), dt)); vely = _mm_add_ss(vely, _mm_mul_ss(reduce_add(accely), dt)); velz = _mm_add_ss(velz, _mm_mul_ss(reduce_add(accelz), dt)); _mm_store_ss(&m_soa.vel_x[i], velx); _mm_store_ss(&m_soa.vel_y[i], vely); _mm_store_ss(&m_soa.vel_z[i], velz); } // 位置を更新 for (int i = 0; i < m_particle_count; i += 4) { __m128 posx = _mm_load_ps(&m_soa.pos_x[i]); __m128 posy = _mm_load_ps(&m_soa.pos_y[i]); __m128 posz = _mm_load_ps(&m_soa.pos_z[i]); __m128 velx = _mm_load_ps(&m_soa.vel_x[i]); __m128 vely = _mm_load_ps(&m_soa.vel_y[i]); __m128 velz = _mm_load_ps(&m_soa.vel_z[i]); posx = _mm_add_ps(posx, _mm_mul_ps(velx, dt)); posy = _mm_add_ps(posy, _mm_mul_ps(vely, dt)); posz = _mm_add_ps(posz, _mm_mul_ps(velz, dt)); _mm_store_ps(&m_soa.pos_x[i], posx); _mm_store_ps(&m_soa.pos_y[i], posy); _mm_store_ps(&m_soa.pos_z[i], posz); }
すっごく冗長になってしまいましたが、__m128 を float に置換してみると意味は明瞭になるんじゃないかと思います。
速度更新フェーズの内側のループで 4 パーティクルとの距離計算を同時に行い、最後に 4 つの結果を reduce add して統合しています。recuce_add() の中身はそのまんま __m128 の中の 4 要素を足しあわせているだけです。
inline __m128 reduce_add(__m128 v1) { __m128 v2 = _mm_movehl_ps(v1, v1); // z,w,z,w v1 = _mm_add_ps(v1, v2); // xz,yw,zz,ww v2 = _mm_shuffle_ps(v1, v1, _MM_SHUFFLE(2, 2, 2, 2)); // yw, yw, yw, yw v1 = _mm_add_ss(v1, v2); // xzyw, ... return v1; }
実行結果。
Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms (new!)
ベタな SSE 化からさらに倍以上速くなりました。Update のたびに毎回 SoA に並べ替えて計算して AoS に戻しているのでトータル処理量は増えているはずですが、それでもこれだけ効果があります。
ISPC
先に少し触れたように、近年の x86 CPU には AVX と呼ばれる命令群が備わっており、これを使うと 8 つの float を同時に計算できます。理想的なケースでは本当に SSE のほぼ倍の速度が出せます。ぜひ使いたいところです。
しかし、AVX が使える CPU は Intel Sandy Bridge (2011) 以降であり、まだ十分に普及しているとは言えません。なので AVX を使うにしても SSE 実装と AVX 実装両方を用意して実行時に使える方を選ぶのが実用的なやり方になります。
とはいえ、両方実装するのは面倒です。今回の例くらい単純なケースでは SSE, AVX 両方実装するのも大したコストではありませんが、ここでは紹介もかねて ISPC を使ってラクをしてみます。
http://ispc.github.io/
ISPC は SIMD に特化したプログラミング言語です。
SIMD の各レーンを実行単位と見立てた記述をするようになっています。ISPC で記述してコンパイルすると、SSE, AVX, ARM (NEON) それぞれに最適化されたコードを出力することができます。SSE と AVX に関しては、両方の実装を用意して実行時に使える方を選ぶのを自動的にやってくれます。コンパイル結果は .obj と .h として出力され、簡単に C/C++ のプログラムにリンクできます。Windows はもちろん、Mac、Linux、PS4 向けにもクロスコンパイルできます。
詳しい解説はこちらに委ねますが、ここまで読んでくれた方であれば、最初のストレートな C++ 実装に近い記述で、上の SIMD & SoA と同じ内容にコンパイルできる言語、という説明がわかりやすいんじゃないかと思います。
SoA <-> AoS 化は C++ 側で行い、それを ISPC で書いたカーネルに渡して処理します。ISPC のコードは以下のようになります。
// パーティクル同士の押し返し for(uniform int i=0; i<particle_count; ++i) { uniform float3 pos1 = {pos_x[i], pos_y[i], pos_z[i] }; float3 accel = {0.0f, 0.0f, 0.0f}; foreach(j=0 ... particle_count) { float3 pos2 = {pos_x[j], pos_y[j], pos_z[j] }; float3 diff = pos2 - pos1; float dist = length(diff); float3 dir = diff / dist; float3 a = dir * (min(0.0f, dist-(particle_size*2.0f)) * pressure_stiffness); accel = accel + (a * select(dist > 0.0f, 1.0f, 0.0f)); } uniform float3 vel = {vel_x[i], vel_y[i], vel_z[i] }; vel = vel + reduce_add(accel) * dt; vel_x[i] = vel.x; vel_y[i] = vel.y; vel_z[i] = vel.z; } // 位置を更新 for(i=0 ... particle_count) { float3 pos = {pos_x[i], pos_y[i], pos_z[i] }; float3 vel = {vel_x[i], vel_y[i], vel_z[i] }; pos = pos + (vel * dt); pos_x[i] = pos.x; pos_y[i] = pos.y; pos_z[i] = pos.z; }
実にすっきりしました。これを SSE をターゲットにしてコンパイルすると上の SoA & SSE のコードとほぼ同じ内容のバイナリになりますし、AVX をターゲットにすれば AVX 実装のできあがりです。
AVX をターゲットにする際の注意点として、SSE が 16 byte align が必要だったように、AVX だと 32 byte align が必要になります。なので今回は最初からパーティクルは 32 byte align でメモリを確保しています。
これをビルドして実行してみます。
Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms ISPC (ST) : 12.3ms (new!)
さらに 1.6 倍も速くなりました。処理内容は SSE & SoA と同じなので、このスピードアップは AVX 化によるものと言えます。
ISPC の便利さは SIMD プログラミングを長いことやってる人ほど身にしみるんじゃないかと思います。一頃に比べるとコンパイラのバグリーな動作は少なくなり、対応プラットフォームも増えたので、実戦投入も検討に値するレベルになってきたんじゃないでしょうか。
余談ですが、ISPC の "SIMD の各レーンを実行単位に見立てる" という考え方はシェーダプログラミングにも当てはまり、近年の NVIDIA や AMD の GPU ではシェーダプログラムは 32 の SIMD レーン (NVIDIA が "Warp"、AMD が "Wavefront" と呼んでるもの) それぞれで並列に実行されるようになっています。なので、ISPC はシェーダプログラミングのパラダイムを CPU の SIMD で実装したもの、とも言えると思います。
そんなわけで、色々頑張った結果最初のストレートな C++ 実装から 10 倍くらい速くなりました。これをマルチスレッド化までやると最近の Core i7 の比較的いいやつだと 8192 パーティクルが 60 FPS で動くようです。(= 67108864 回の距離計算が 16ms 以内で終わる!)
Unite 2015 Tokyo でデモした MassParticle はハッシュグリッド法で近隣パーティクルのみと衝突計算する最適化を入れていますが、衝突計算自体は今回の例と全く同じになっています。
解説はここまでです。記事中のソースは簡略化しているので、より詳細に実装を知りたい場合 github に上がってるソースを見ることをおすすめします。SIMD はアルゴリズムが単純でメモリアクセスが少ないケースで特に効果的です。弾幕やパーティクルなど、単純なオブジェクトの大量処理は SIMD に向いた問題なので、数出したい方は足を踏み入れてみるといいでしょう。
あと、もっと速くする方法がありましたらご一報ください。
C#
おまけ。最初のストレートな C++ 実装を C# で再実装してみました。
ソース
実行結果:
Plain C# (ST) : 1196.1ms (new!) Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms ISPC (ST) : 12.3ms
Unity でスクリプトに速度を求めるならプラグイン書いた方がいい、というのがどういうことなのかよくわかると思います。
一応 C# を弁護しておくと、こういう数値計算の類は C# が苦手な処理の最たるものであり、ここまで差が出るケースはレアなはずです。また、C# でもバックエンドが最新の .Net だったりするともうちょっとマシな結果になると思います。
あと、元の C++ 実装を最適化 無効 でビルドすると C# の方が速くなりました。この結果を見ると IL2CPP のアプローチは意外と合理的なんじゃないかと思えてきます。
Compute Shader
おまけ 2。Compute Shader でも実装してみました。
ソース
実行結果:
CPU: Intel(R) Core(TM) i7-4790K CPU @ 4.00GHz GPU: NVIDIA GeForce GTX 970 Plain C# (ST) : 1196.1ms Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms ISPC (ST) : 12.3ms Plain C# (MT) : 224.7ms Plain C++ (MT) : 33.4ms SIMD (SSE) (MT) : 12.1ms SIMD SoA (MT) : 5.1ms ISPC (MT) : 3.2ms Compute Shader : 1.45ms (new!)
Compute Shader と比較する場合、CPU 側もマルチスレッド化していないとフェアじゃないのでそうしています。Compute Shader の処理時間は、Dispatch() を呼ぶ直前から計算結果を CPU 側に書き戻すまで、で測定しています。(Dispatch() から制御が戻った時点では実際の処理はまだ終わってないので) なので CPU 側にデータを移す時間分 Compute Shader に不利に働く条件になっているはずですが、これだけの性能が出ます。NVIDIA NSight で純粋な処理時間も見てみたところ、大体 1.1ms くらいという感じでした。

ゲームでは GPU は大抵レンダリングで忙しいので GPGPU は使いどころが難しいですが、グラフィックはそこそこに留めてこの計算パワーを活かしたゲームデザインを模索してみるのも面白いかもしれません。
Unite 2015 Tokyo
Unity ユーザー向け開発者イベント、Unite 2015 Tokyo で公演しました。上はそのスライドになります。タイトルの通り、基本的にこの blog の過去の検証記事をまとめた内容になっています。
Unite に来る人でこういう内容を求めている人はそんなにいない (シェーダー書く Unity ユーザーの割合はかなり少ない) のがわかっていたので、資料作りにはかなり悩みました。最終的に、あまり深くなり過ぎない程度にレンダリングとアップデート両方を解説した…つもりです。なので、実装について詳しく知りたい場合は元となったこの blog の検証記事とソースを見た方がいいでしょう。(これ これ これ)
少なくともデモはそれなりにインパクトがあったのが見て取れたので、Unity でプログラミングやゲーム開発を始めたような層がこういう領域に興味を持つきっかけになればいいなあ…という感じです。

そんな私の悩みをよそに、本国から来日してきた Unity エンジニアによるセッションでは遠慮なくレンダリング方程式が出てきたりしていたそうで、Unite 終了後脱力していました。まあ、次話す機会があったとしてもそこまでマニアックな話はしないつもりです。
自分的に今回の目玉は MEVIUS FINAL FANTASY の話。奇しくもスクエニから Unity に移った直後にちょっとだけこのプロジェクトに関わる機会に恵まれたのですが、内側と外側両方から見て、改めてスクエニの開発力の高さを実感させられました。公開資料からもその片鱗が伺えるのではないかと思います。
十分な開発力を持ってるところでも、誰が実装しても同じ結果になるような部分にかける手間を省くため、苦手な領域の最低限のクオリティを担保するため、などを目的にゲームエンジンを導入する意義はあると思います。やりたくない部分は既にあるものに任せて、得意な部分により注力する、という考え方です。その得意な部分もゲームエンジンに表現を縛られる必要はなくて、こだわりがある領域や独自性を出したい部分は遠慮無く独自実装していいし、むしろ積極的にやるべきだと思っています。
(私がプライベートでわざわざ Unity 使って Unity っぽくないゲームとかを作ってるのも、それを示したいというのが 1 つのモチベーションとしてあります)
あとは、今回の Unite で 10 年ぶりに専門学校時代の先生に会って「名前と顔で記憶に引っかかって、パーティクルを見て確信した」的なことを言われたのが嬉しいやら感慨深いやらでした。CPU に火を注ぎ続けてもう 10 年経つんだなあと。10 年後の自分も相変わらず CPU に火を注ぎ続けていることを望みます。



rendering fractals in Unity5

Unity5 になってレンダリング機能の柔軟性が大きく増しました。
新たに追加された CommandBuffer により、Unity のレンダリングパスのほとんど任意のタイミングに任意の描画コマンドを差し込むことができるようになりました。また、deferred shading レンダリングパスが新たに追加されました。Unity4 にあったのは deferred lighting でしたが、今度のはリッチな G-Buffer を持ったちゃんとした deferred shading です。
CommandBuffer と deferred shading を併用することにより、Unity のレンダリングパスで用いられている G-Buffer を加工したり、ライティングを独自処理に差し替えたりといったことができるようになります。試しにこれらを用いてフラクタル図形をレンダリングしてみました。
https://github.com/i-saint/RaymarchingOnUnity5
http://primitive-games.jp/Unity/RaymarcherUnity5.html
本記事の内容のソースコードと WebPlayer ビルドはこちらになります。Unity5 からフリー版 (Personal Edition) でも全レンダリング機能を使えるようになったので、気軽に手元で試せるようになったんじゃないかと思います。
元ネタはしばらく前の この記事。distance function & raymarching を用いて G-Buffer を生成し、それに対してライティングを適用する、というものです。
deferred shading の場合、ポリゴンモデルは G-Buffer の生成のみに用いられ、ライティングの段階ではラスタライズされたデータである G-Buffer が用いられます。裏を返すと、G-Buffer さえ適切に生成できれば、どんなものに対しても適切にライティングを施すことができます。
3D モデル の表現はポリゴンモデル以外にもいくつかあり、それらも G-Buffer の生成に活用できます。今回用いる distance function もその 1 つです。
distance function & raymarching は demoscene の世界でよく使われているレンダリング手法で、ポリゴンモデルの代わりに数式で 3D モデルを表現してピクセルシェーダでそれを可視化する、というものです。この数式は図形との距離を返す関数で、故に distance function と呼ばれます。distance function を用い、ray を飛ばして段階的に図形との距離を求めて可視化していく手法が raymarching と呼ばれます。
下図のように ray が進んでいくことから、sphere tracing と呼ばれることもあります。ボリュームデータを可視化する手法も raymarching と呼ばれるので、区別するにはこちらの方がいいのかもしれません。

distance function や raymarching の詳細は元ネタ記事に委ねて、実装の詳細です。
demoscene の世界では大抵ライティング処理まで 1 パスでやってしまいますが、前述のように今回は G-Buffer の生成のみに distance function & raymarching を用いてライティングは Unity に委ねるという手法を取ります。これにより Unity の通常の 3D オブジェクトと一貫したライティングを行うのが狙いです。
実際の手順は単純で、CommandBuffer を用いて G-Buffer パスの後 (CameraEvent.AfterGBuffer) に fullscreen quad を一枚描く処理を追加し、ピクセルシェーダで G-Buffer を生成します。他は通常通りで、ライティングやポストエフェクトなどは標準機能を使います。
CommandBuffer の内容は以下になります。
CommandBuffer cb = new CommandBuffer(); cb.name = "Raymarcher"; cb.DrawMesh(quad, Matrix4x4.identity, material, 0, 1); camera.AddCommandBuffer(CameraEvent.AfterGBuffer, cb);
これだけです。ちなみに、実行タイミングが CameraEvent.BeforeGBuffer/AfterGBuffer であればレンダーターゲットは既に G-Buffer が指定されており、自分で指定する必要はないようです。
ピクセルシェーダが今回の肝で、distance function を raymarching するわけですが、distance function は今回はよく知られてるフラクタル図形の式を適当に見繕ってきました。
http://glslsandbox.com/e#23658
(map() 関数で式を選びます)


左: Tglad's formula と呼ばれているらしい式。右: Pseudo-Kleinian と呼ばれているらしい式。どちらもびっくりするくらい短い式で綺麗な絵が出てきます。
raymarching でレンダリングするオブジェクトと Unity のシーン上のオブジェクトの位置関係を正しくするには、当然ながら raymarching で用いる座標系と Unity のシーンの座標系を一致させる必要があります。このために必要な情報は、カメラの位置、正面方向、上方向、focal length ( 1.0/tan(fovy*0.5) ) になります。
これは知っていれば簡単で、全て view 行列と projection 行列から抽出できます。ただ、位置に関しては復元にちょっとばかし計算コストがかかるため、Unity が提供している組み込み変数 _WorldSpaceCameraPos を利用した方がたぶんいいです。結論としては以下のコードで必要な情報を抽出できます。
float3 GetCameraPosition() { return _WorldSpaceCameraPos; }
float3 GetCameraForward() { return -UNITY_MATRIX_V[2].xyz; }
float3 GetCameraUp() { return UNITY_MATRIX_V[1].xyz; }
float3 GetCameraRight() { return UNITY_MATRIX_V[0].xyz; }
float GetCameraFocalLength() { return abs(UNITY_MATRIX_P[1][1]); }// 参考用、view 行列から復元する版 GetCameraPosition()
float3 GetCameraPosition()
{
float3x3 view33 = float3x3(UNITY_MATRIX_V[0].xyz, UNITY_MATRIX_V[1].xyz, UNITY_MATRIX_V[2].xyz);
float3 rpos= float3(UNITY_MATRIX_V[0].w, UNITY_MATRIX_V[1].w, UNITY_MATRIX_V[2].w);
return mul(transpose(view33), -rpos);
}プラットフォームによって変わる可能性を考慮して関数にしています。右方向 (GetCameraRight()) に関しては正面方向と上方向の外積で算出できますが、せっかくそこにあるので使っています。
raymarching で ray の位置が求め、近隣ピクセルの勾配から法線を推測したら、それらを G-Buffer として出力します。G-Buffer を生成するためのピクセルシェーダの出力は以下のようになります。
struct ps_out
{
half4 diffuse : SV_Target0; // RT0: diffuse color (rgb), occlusion (a)
half4 spec_smoothness : SV_Target1; // RT1: spec color (rgb), smoothness (a)
half4 normal : SV_Target2; // RT2: normal (rgb), --unused, very low precision-- (a)
half4 emission : SV_Target3; // RT3: emission (rgb), --unused-- (a)
float depth : SV_Depth; // 今回は depth も独自に出力
};注意点として、normal は符号なしデータ (RGBA 10, 10, 10, 2 bits) で格納されるため、格納時は *0.5+0.5、取得時は *2.0-1.0 してやる必要があります。
また、Stencil を有効にして 7 bit 目を立てる (128 を足す) 必要があります。Stencil の 7 bit 目が立っていないピクセルはライティングされません。
それと、今回のようなケースでは depth も独自に計算して出力する必要があります。通常はピクセルの位置の depth が自動的に出力されるので気にする必要はないのですが、今回はそれだと full screen quad の depth (=0) が出力されてしまいます。今回ほしいのは ray が到達した地点の depth です。
depth を独自に出力する場合、上記のようにピクセルシェーダの出力に SV_Depth セマンティクスつきのデータを加えればいいのですが、depth の算出方法は Direct3D と OpenGL 系で若干違うため、以下のような対応も必要になります。
float ComputeDepth(float4 clippos)
{
#if defined(SHADER_TARGET_GLSL)
return (clippos.z / clippos.w) * 0.5 + 0.5;
#else
return clippos.z / clippos.w;
#endif
}あとはピクセルシェーダの中で depth = ComputeDepth(mul(UNITY_MATRIX_VP, float4(ray, 1.0))); のようにすれば ok です。これにより、raymarching で生成した図形と Unity の 3D オブジェクトが正しく前後するようになり、ライティングも一貫します。SSAO の類をかけるとより馴染むでしょう。
ちなみに、今回は当たり判定まではやっていませんが、distance function はその名の通り図形との距離を算出する関数であるため、CPU 側コードで同内容の関数を書けば当たり判定も取れるはずです。GPU パーティクルなどであれば G-Buffer を見てスクリーンスペースで当たり判定を取るテクニックも使えます。
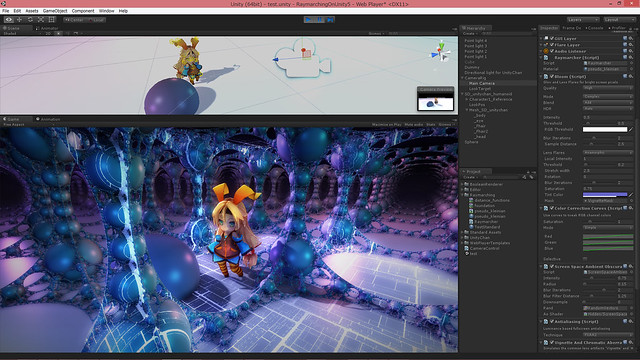
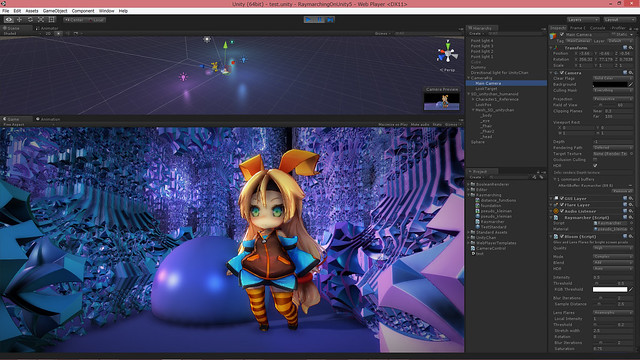
整合性確認のために (SD) Unity ちゃん にご登場頂きました。Unity ちゃんの隣の球も通常の Unity の 3D オブジェクトです。前後関係もライティングも一貫しているし、影もちゃんと落ちているのが見て取れると思います。
raymarching & distance function を使うと、ポリゴンベースの手法に見慣れている人ほど面食らう面白い絵を出せるんじゃないかと思います。
ただ、問題として、制御が難しくて細かい調整が大変なのと、激烈に重いというのがあります。
頂点負荷はほとんどないものの、ピクセルシェーダがものすごく重くなるため、GPU がしょぼいくせに解像度はやたら高い iOS / Android デバイスでは現状まともな速度を出すのは絶望的です。ノート PC 用の GPU でもかなり厳しいです。デスクトップ PC や PS4 で限定的な使用であればなんとか実用に耐える…といいな、というレベルです。
とはいえ、比較的少ない労力で超ディティールの絵を出せるので、この手法がごく普通に使えるまでにハードウェアが進化した時、特に小規模開発チームにとって強力な武器になりうるはずです。
Unity4 で今回のようなことをやりたい場合、標準のレンダリングパイプライン使うのは諦めて全部自力でやるしかなかったのですが、Unity5 になって、このように特殊な処理だけ自力でやって他は Unity に任せる、というのがやりやすくなりました。自分的にすごく嬉しい変化です。
また、今は CommandBuffer には DrawProcedural() がありませんが、近い将来追加されるそうです。そうなったら、インスタンシングで描いたオブジェクトを Unity の deferred パスでライティングする、ということができるようになります。これは自分的に長らく待ち望んでいたものです…!
CommandBuffer & deferred shading が加わったことで、raymarching 以外にも様々な G-Buffer 加工トリックが実現できるようになったはずです。近い先以前やった モデルの boolean 演算 などを使いやすい形にして移植してみる予定です。
[2016/03/09] 追記
下記の CommandBuffer.SetRenderTarget() の問題はいつの間にか修正されているようで、正確なタイミングは不明ですが少なくとも 5.2 系では RenderTarget 指定は機能するようです。
余談ですが、実装上の注意点というか自分がハマった点。
CommandBuffer.SetRenderTarget() には現状任意の RenderTexture を設定することはできないようです。builtin 型か、temporary なものに限られます。コードを見た方がどういうことか理解しやすいと思います。
var cb = new CommandBuffer(); { // これは ok var rt = new RenderTargetIdentifier[4] { BuiltinRenderTextureType.GBuffer0, BuiltinRenderTextureType.GBuffer1, BuiltinRenderTextureType.GBuffer2, BuiltinRenderTextureType.GBuffer3, }; cb.SetRenderTarget(rt, BuiltinRenderTextureType.CameraTarget); } { // これも ok int rtid = Shader.PropertyToID("MyRenderTarget"); cb.GetTemporaryRT(rtid, -1, -1, 0, FilterMode.Point); cb.SetRenderTarget(rtid); } { // これは機能しない! var rt = new RenderTexture(1280, 720, 0); cb.SetRenderTarget(rt); }
幸い temporary なものも勝手に消されたりはしないようで、複数フレームにまたがる処理なども問題なく実装できました。必要であれば OnPostRender() とかの中で内容をコピーするシェーダを走らせれば RenderTexture に内容を移すこともできます。
CommandBuffer については 公式にいいサンプルが提供されており、導入には最適だと思われます。
また、いつも通り、込み入ったシェーダを書く場合、公式に提供されている Unity の builtin シェーダのソース が役に立つというか事実上必須になります。
また、Unity5 になって稀に Direct3D の時だけ挙動がおかしくなるシェーダがあるのですが、#pragma enable_d3d11_debug_symbols を入れると直るという現象に遭遇しています。気持ち悪いですが明確な原因は突き止められず、ひとまずこれで凌いでいます。
それと、どうも WebGL では deferred パスは使えないようです。たぶん WebGL 1.x には multi render target がないためで、だとすれば対応は WebGL 2.0 を待つしかない気がします…。
blue impulse / TokyoDemoFest2015
webplayer: http://primitive-games.jp/Unity/blue_impulse/
source: https://github.com/i-saint/BlueImpulse
TokyoDemoFest2015 にて PC demo を発表しました。その映像、バイナリ、ソース一式を公開します。
今回も Unity 製です。会場のマシン (Windows & GeForce GTX 780) で動けばいいやという想定で作ってるので相当重いです。Direct3D11 必須。
今まで積み上げてきたリソースを組み合わせて短期間で映像作品に仕立ててみよう、というチャレンジのもとに制作に挑みました。水面やポストエフェクトの追加などレンダリングエンジンへの機能追加に約 1 週間、シーンデータの作成に約 1 週間で、製作期間は 2 週間くらいです。
今回もサウンドは カワノさん が担当しており、本格的にシーン制作にとりかかるよりも先に求めていたイメージずばりな曲を上げてきてくれて、制作のはずみになりました。
レンダリングエンジンは独自のもの (exception reboot と同じ) であり、Unity 標準のシェーダは一切使っていません。また、意識して縛りプレイしたわけではないですが、結果的に今回も使ったモデルは Cube と Quad だけになりました。
ゲームエンジンを使う場合、今回みたいに レンダリングエンジンだけ他のプロジェクトに流用し、そのフィードバックを元プロジェクトに返す、みたいなことが簡単にできるのが 1 つの強みである、というのが今回得られた実感でした。レンダリングエンジンを鍛えるためにも、今回みたいな試みはたまにやっていきたいところです。
今作はいつも以上にポストエフェクトに依存した絵作りになっています。
GBuffer 書き出してライティングした状態。
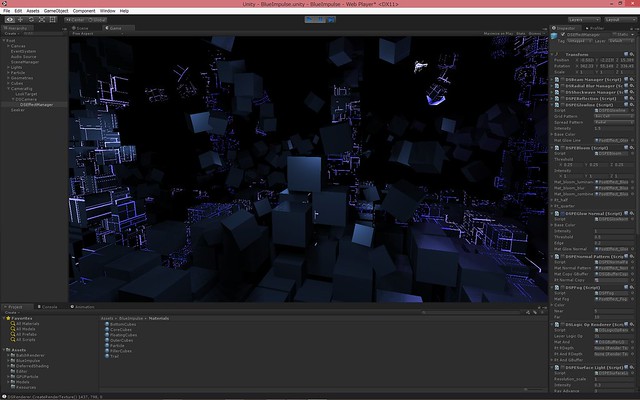
視線->法線の角度が浅いところを明るくするエフェクト、ブルーム、スクリーンスペース反射を加えた状態。
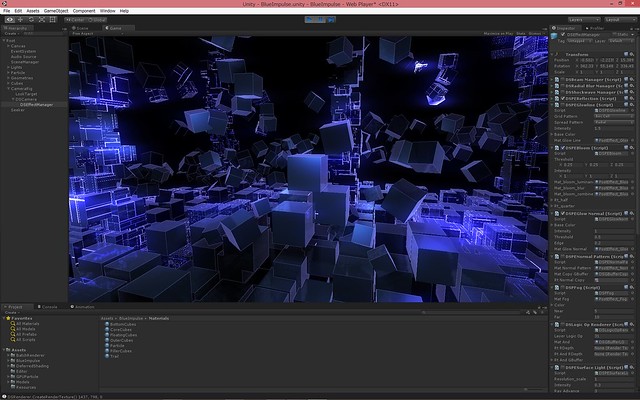
水面&コースティクスエフェクトを加えた状態。
これらを実装するにあたって鍵となるノイズ関数は、こちらに使われてるものを拝借いたしました。一般的な perlin ノイズより軽量で結果は十分良好なように見えます。
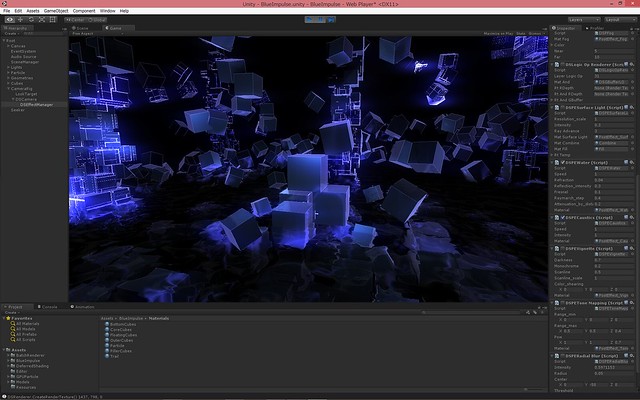
トーンマッピング、指向性ブルーム、走査線、周辺減光を加えて最終イメージ図。
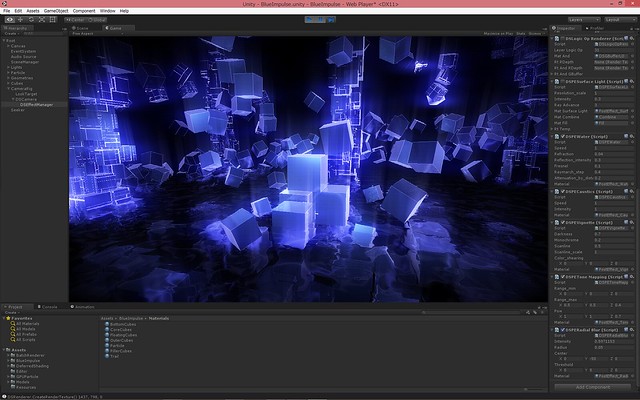
パーティクルは以前実装した GPU パーティクルです。trail も compute shader で頂点を生成しています。

一部の要素は過去の記事で詳細な解説がなされています。
deferred shading in Unity - primitive: blog
Temporal Screen Space Reflections - primitive: blog
render massive amount of cubes in Unity (2) - primitive: blog
pseudo-instanced drawing in Unity - primitive: blog
TokyoDemoFest には毎年行っていますが、今回からはオーガナイザの一人として運営の方にも関わっています。
今回は間違いなく過去最高に盛り上がった回で、投稿作品も多く、レベルも高く、いろんな方と技術トークできて幸せなひとときでした。
特によっしんさん (@yosshin4004) の Optical Circuit が信じられないくらいすごくて、初めて elevated を見た時級の衝撃を受けました。魔法って実在するんだ、というのを改めて実感しました。
バイナリ
TokyoDemoFest は来年の開催に向けてスポンサーをやってくれる方 / 企業様を募集しております。
pseudo-instanced drawing in Unity
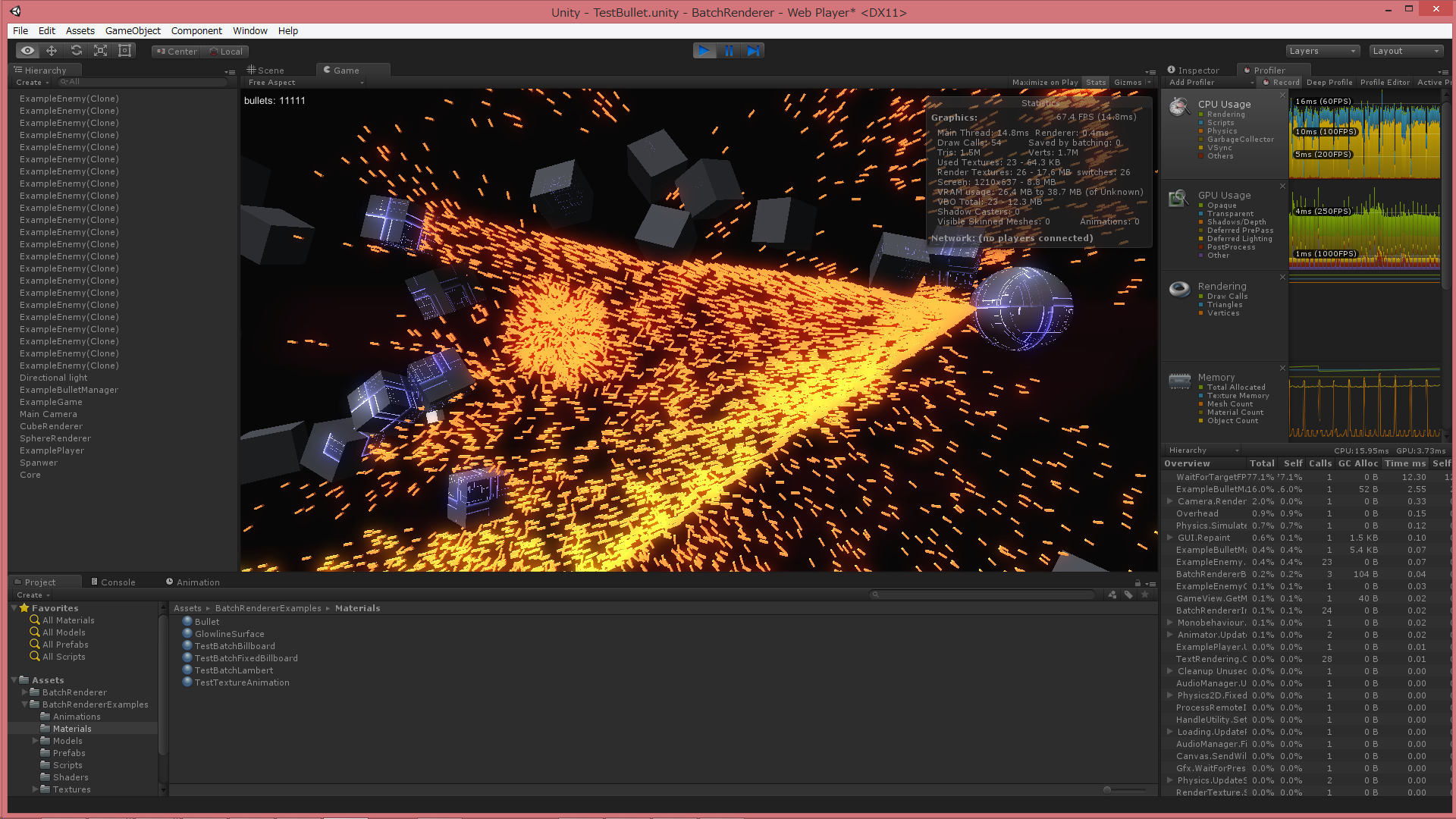
Unity で大量のオブジェクトを描画するスクリプトを書きました。
https://github.com/i-saint/BatchRenderer
簡単な使用例
いつも通り弾幕やらパーティクルやらを描くのを想定した代物ですが、割と簡単に使えてポータブルな作りになっています。Windows で D3D11, D3D9, OpenGL モードでいずれも動作。Android でも動作を確認しています。
スクリプトの使い方については上記ページを参照していただくとして、この記事ではこのスクリプトを作る過程で得られた (バッド) ノウハウ群を書き残しておこうと思います。過去の記事と内容が被ってる部分が多くありますが、その多くは本記事でより洗練されています。
まずこれを作った背景。
OpenGL や Direct3D では、大量のオブジェクトを描画するにはインスタンシング描画を用いるのが一般的です。Unity にも一応 インスタンシング描画機能は備わっているのですが (Graphics.DrawProcedural())、残念ながらこれは Unity の描画パイプラインに組み込むことができません。
Unity の MeshRenderer は描画リクエストをキューに突っ込み、優先順位に基いて実際の描画処理を行うようになっています。一方、Graphics.DrawProcedural() は呼んだその場で描画処理を行います。なので、描画キューに入っているリクエスト全てが処理される前か後にしか描くことができず、不透明オブジェクトパスで描画、みたいなよくある要求を満たせません。
さらに、surface shader も使えなくなるため、Unity のシェーダと一貫したライティング処理を行うのも難しくなります。おまけに現状 Direct3D11 が使える環境か PS4 でしか使えません。
よって、Unity の描画パイプラインを使いつつポータブルに大量のオブジェクトを描画したい場合、他の手を考える必要があります。BatchRenderer はそういう要求のもとに作られました。
多数のオブジェクトを描画したい場合、一番ストレートな方法は描きたいオブジェクトの数だけ GameObject (MeshRenderer) を用意する、というものですが、まあ、遅くて現実的ではありません。アクティブな GameObject は存在するだけで結構な負担になります。
他に使えそうな手として、Graphics.DrawMesh() という API があります。これは Mesh を描画するリクエストをキューに突っ込む、というもので、つまり MeshRenderer がやってることを GameObject なしで実現できる API になります。
GameObject なしで Unity のレンダリングパイプラインを使う描画処理をやるにはたぶんこの API を使うしかないのですが、単純に描きたいオブジェクトの数だけ DrawMesh() を呼ぶ、というも遅くてやや厳しいです。描画キューを処理するにあたって内部的に複雑な前処理が行われるため、1 つの drawcall が OpenGL や Direct3D の世界よりずっと重くのしかかります。
数千くらいなら個別 Graphics.DrawMesh() でもなんとかなるかもしれませんが、それ以上になるともう一歩踏み込んだ方法が必要になります。
より大量のオブジェクト描画を実現するため、BatchRenderer では擬似インスタンシングを用いています。これは 1 つの Mesh に多数のモデルを格納し、頂点シェーダで各モデルを動かすことで 1 回の Graphics.DrawMesh() で多数のオブジェクトを描く、というものです。
Mesh オブジェクトは 1 つにつき 65000 頂点までしか格納できないため、65000 / モデルの頂点数 が 1 回の Graphics.DrawMesh() で描ける限界になります。 例えば cube の場合、24 頂点なので 2708 個が 1 つの Mesh に収まる数になります。2708 個、頂点の位置も法線も同じ cube がぎっしり重なって格納されているイメージです。後述のモデル ID だけがそれぞれのモデルで異なります。
より詳細に BatchRenderer の内部で行われていることを説明すると、まずユーザーが指定した Mesh のデータをコピーして、上記のような多数のモデルが格納された Mesh を生成します (65000 / モデルの頂点数 分)。この時、Mesh.uv2 にはそのモデルが何番目かという ID を格納します。(元の uv2 は失われますが、あまり使われないので妥当な格納場所と判断)
次に、ユーザーが指定した Material の複製を作ります。1 回の Graphics.DrawMesh() で描ききれない場合、複数回 Graphics.DrawMesh() を呼ぶ必要がありますが、その回数分の Material を必要に応じて生成します。各 Material には、オブジェクトの ID が何番目から始まるか、という情報を付与します。この開始 ID + モデルの ID でオブジェクトの ID を得られるようにするわけです。
このオブジェクト ID を元に頂点シェーダ内でオブジェクトの位置や回転などの情報を取得し、変形処理を行って描画します。
(例えば cube を 10000 個描きたい場合、10000/2708 で 4 回の Graphics.DrawMesh() が必要なため、Material の複製も 4 個作ります。各マテリアルの開始 ID は 0, 2708, 5416, 8124 となります。 ちなみに 10000 以降のモデルは頂点シェーダで vertex.xyz = 0.0 として画面に出ないようにします)
頂点シェーダからオブジェクトの位置などの情報にアクセスできるようにするには、事前にスクリプト側でデータを集めて GPU 側にアップロードしておく必要があります。これがなかなか厄介で、今回の話の主題はここになります。
頂点シェーダからアクセスできる任意長のデータは、テクスチャ (sampler2D) かバッファ (StructureBuffer) の 2 種類になります。
バッファの場合話は単純で、スクリプトから ComputeBuffer オブジェクトを生成し、それを Material.SetBuffer() でアタッチし、、以降 ComputeBuffer.SetData() でデータを更新するだけです。
とても簡単でまあまあ速くて任意の構造 (struct) のデータを格納でき、あとフリー版でも使えるというメリットもあります。しかしながら、現状 Direct3D11 が使える環境か PS4 でしか使えません。
近年はモバイルデバイスもハードウェア的にはこの機能はサポートしており、将来的には今回のような用途にはバッファを使うのが定石になると思われますが、残念ながらポータビリティを考慮すると現状テクスチャを使う方が有力な選択肢になります。
テクスチャの場合 Texture2D …を使いたいところですが、Texture2D はなぜか float や half のフォーマットをサポートしていないため、これらをサポートしている RenderTexture で代用する必要があります (よって、フリー版では使えません)。そして RenderTexture にはなぜか SetPixels() がないため、面倒なことをする必要があります。
RenderTexture に任意のデータを書き込む現実的な方法はたぶん 2 通りで、1 つはプラグインを用いる方法、もう 1 つは Mesh にデータを格納して Graphics.DrawMeshNow() で書き込む方法です。
プラグインを用いる方法。
Texture 一族は GetNativeTexturePtr() という、ネイティブ API (OpenGL や Direct3D) のテクスチャオブジェクト (ID3D11Texture2D* など) を取得するメンバ関数を提供しています。なので、ネイティブ API を用いてテクスチャにデータを書き込むプラグインを作り、スクリプトからテクスチャオブジェクトとデータポインタを渡せば目的を達成できます。
この方法はデータのコピーに mono を一切介さないため速いというメリットがあります。
当然ながら、プラグインはプラットフォームごとに個別の処理を書いてビルドする必要があります。プラットフォームによってはプラグインを組み込むのが大変で、実装難度が高くなります。また、WebPlayer や WebGL (Unity5) だと使えないというポータビリティ面での問題もあります。
また、環境によっては float のテクスチャはサポートしておらず、half のみだったりするので、どちらでも対応できるようにしておいたほうがいいでしょう。
Mesh & 描画による方法。
Mesh.vertices などにデータを格納し、データを書き込むシェーダを用意し、データ用 RenderTexture をレンダーターゲットに設定して Graphics.DrawMeshNow() で描くことで、Mesh に格納したデータを RenderTexture に移すという方法です。
ほとんどのプラットフォームで使えてスクリプトだけで完結するポータビリティが高い方法ですが、まず Mesh にデータを格納するのが遅い上、それを GPU にアップロードして drawcall を発行してそれが完了するのを待たないといけず、他の方法と比べて致命的に遅いという問題もあります。
実装の際の注意点として、プラットフォームによっては Mesh の normals, tangents, colors は内部的に正規化されたり clamp されたりするようです。(少なくとも Android では。ハマりました…) よって、ポータビリティを考えるとデータの輸送には vertices, uv, uv2 しか使えません。その分 Mesh にデータを書き込んで Graphics.DrawMeshNow()、を何度も繰り返すことになります…。
テクスチャを使うアプローチ共通の注意点として、格納できるデータは float/half の羅列に限られるので、任意の構造体を格納できるバッファに比べると柔軟性は落ちます。とはいえ、ビットフラグとかを格納するのでなければあんまり問題にはならないとは思われますが。
また、古い環境では同時に使えるテクスチャの数の上限が大きな障害になります。(Direct3D9 / ShaderModel 3.0 だと 4 つ。4 つ!!)
ちなみに頂点シェーダでテクスチャにアクセスするには tex2Dlod() を用います。
まとめると、任意のデータを GPU に転送してシェーダからアクセスできるようにする方法は大きく以下の 3 通りになると思われます。
1. ComputeBuffer
pros
・実装が非常に楽
・任意のデータ構造を格納可能
・フリー版でも使用可能
cons
・現状 Direct3D11 が使える環境か PS4 でしか使えない
2. RenderTexture にプラグインからデータを書き込む
pros
・速い
cons
・プラットフォーム毎の個別対応が必要
・WebPlayer や WebGL では使えない
3. RenderTexture に Mesh 経由でデータを書き込む
pros
・とてもポータブル
cons
・とても遅い
速度: RenderTexture&プラグイン > ComputeBuffer >>>>>>>> RenderTexture&Mesh
ポータビリティ: RenderTexture&Mesh > RenderTexture&プラグイン > ComputeBuffer
実装容易性: ComputeBuffer > RenderTexture&Mesh > RenderTexture&プラグイン
どれもすごく一長一短で悩ましいです。
BatchRenderer はこの 3 種類を全て実装し、ComputeBuffer か RenderTexture&プラグイン が使えなければ RenderTexture&Mesh にフォールバックするようにしています。
以下余談。
GeometryShader を使うと状況によっては一回の Graphics.DrawMesh() で描ける数をさらに増やせるのですが、今回はそこまでやっていません。理由はいっぱいあって、Unity の GeometryShader は Direct3D11 が使える環境でしか使えないこと (今は他に使える環境があるかもしれませんが、いずれにせよポータビリティは低いです)、surface shader と併用できないこと、ビルボードなどの本当に単純なモデルにしか適用できないこと、Unity の GeometryShader サポートがいまいちやる気が感じられないこと、などです。
また、BatchRenderer ではやっていませんが、応用として Graphics.DrawProcedural() の Unity のレンダリングパイプラインに載せられるバージョンに近いものも実現できます。
まず実際のモデルデータを ComputeBuffer に格納。それとは別に vertices に頂点 ID のみを格納した Mesh を用意。描画の際、頂点シェーダは 頂点 ID をインデックスとして StructuredBuffer から実際のモデルの頂点データを得てそれを出力する、みたいなやり方です。
ComputeShader でモデルを生成してそれを Unity のレンダリングパイプラインに載せて描きたいような場合、現状こういう方法を取る他ないと思われます。
バッドノウハウ以外の何物でもないですが、Direct3D11 世代機能は Unity にはあとづけなのでしょうがない…と納得する他ありません。たぶんきっと将来的に改善されていくことでしょう。
after C87
C87、スペースに立ち寄ってくださった方々、ありがとうございました。
exception reboot 体験版ですが、Visual Studio 2013 ランタイムが入ってないとパーティクルや背景が出ないというミスをやらかしてしまいました…。同現象に見舞われている方はこちらをインストールしてお試しください。
http://www.microsoft.com/ja-JP/download/details.aspx?id=40784 (vcredist_x86.exe の方)
また、ビデオカードによってはエフェクトが正常に出ないようです。今後調査して直していきます。
今回 1 ステージだけなので意識的に難しめにしています、が、ちょっとやりすぎたかもしれません…。コントローラ対応が中途半端だったり、自機を見失いやすいなどのプレイアビリティに関しては追々改善していきます。
最終的に売り物にしつつもソースは公開、Unity インストールして自力でビルドすれば無料で遊べて、自分でステージ作って他のプレイヤーと共有することもできる、みたいな形を目指しています。2015 年中の完成が目標です。
あとソースに関して、readme に書き忘れたんですが、ビルドには Unity 4.6.1 p1 以降が必要になります。これ未満 (現時点の public release 含む) だとコンパイルエラーが出てしまうと思います。
Assets/Scenes/Title.unity を開くと Unity のエディタ上で今作がプレイできるはずです。
以下、冬コミ版の後書きとか Unity 使ってみた雑感とか。
今回の冬コミ版、パーティクルエンジンとレンダリングエンジン以外の純粋なゲーム部分は、大体 10 日くらいで作っています。ボス作るのが楽しく大部分の時間リソースをそっちに割いてしまい、ステージ道中はかなりお粗末になってしまいました…。メニュー類やシーンの遷移についてはコミケ前日の 1 日で仕上げました。Unity なしでは成り立たない無茶な進行だったと思います。
当初はもうちょっと余裕がある進行にする予定だったんですが、パーティクルとレンダリングの方に時間を取られすぎてしまいました。
自分的今作のハイライト

この半年くらい Unity 絡みの仕事したり、Unity 上で動くデモプログラムを作ったりはしてきましたが、ゲームらしいゲームを作るのは今回が初めてでした。やってみた感じ、やはりこれまでより大分楽で、ステージ作る能率は無印 exception の時より 3 倍以上上がったと思います。
自分で意外だったのが、Unity を使い始めてから、逆に独自のレンダリングエンジンにこだわるようになりました。
Unity を使いはじめる以前は、レンダリングエンジンとか最も既存のゲームエンジンに任せたい部分、と思っていたんですが、いざ実際にゲームエンジンを使ってみると、プログラマー兼アーティストの自分の場合それなりの独自性と最低限のクオリティを両立した絵を出そうと思ったらレンダリングエンジン独自に書くのが一番早い、という結論に至りました。
Unity だとシェーダとレンダリングに絡むコードの変更をゲームに反映させるサイクルが速く、以前よりシェーダ書くのが楽しくなったというのも要因としてあります。
なんか会場で 5 人くらいに「これ Unity 上で動いてはいるけど Unity の機能使ってないですよね?」的なことを言われて意外だったんですが、シェーダとパーティクルが独自なだけで他はちゃんと Unity です。
今どきレンダリングエンジンはゲームエンジンのほんの 1 機能に過ぎないので、自力でやるモチベーションがある部分はフルコントロールして、そうでない部分はゲームエンジンに委ねる、というやり方でいいんじゃないかと思います。自分の場合、パーティクルとレンダリングはそれなりにこだわりがあるものの、エディタ類とかには極力労力を割きたくないのでこういう作り方にしました。自分的にゲームエンジンはレベルエディタとして優秀であればそれで十分です。
今回は Rigidbody、Animation、uGUI あたりを大いに活用しています。
Collider と Rigidbody コンポーネントを追加すれば物理挙動を実現できるお手軽さは素晴らしくて、物理を活用したギミックは今後も増やしていきたいところです。
Animation はステージのスクロールやボスの砲台の制御なんかに使っています。タイムラインエディタはもちろん、任意のタイミングで任意の関数を呼ぶ機能 (Animation Event) が重宝しています。ボスのビームの発射の機能や、ステージのセクションの切り替えは Animation Event による制御です。
uGUI。4.6 から入った UI システムですが、趣味と仕事で過去 3 回くらいインゲーム UI システム書いた身としては、こんな使いやすいのが標準にあることに感動です。UI システムは最低限の機能が揃えばあとは比較的 誰が作っても最終的な見た目にそこまで差は出ない 部分だと思うので、デファクトスタンダードとなりうるものが出てくることには大きな意義あるんじゃないかと思います。
逆に今回 Unity 使ってて不満だった点も挙げると、
C#。Unity というか mono が原因ですが。去年この blog に何度も書いてきましたが、C# で巨大な配列を巡回して処理を行うのは死ぬほど遅くて、この手の処理についてはプラグインか ComputeShader 書く他ありません。pure C# で 10 万パーティクル相互衝突とかたぶん 10 年未来のマシンでも 60 FPS 出すのは無理でしょう。
裏を返すと、プログラマーがゲームデザインをする際最もアドバンテージがあるのがこの領域、とも言えると思います。
スクリプトの実行時編集。スクリプトが編集されるとオブジェクトをシリアライズして、アセンブリをリロードして、オブジェクトをデシリアライズする、という手順を踏みますが、このへんそれなりにちゃんと理解していないと、ちょっとプロジェクトが複雑になると破綻するんじゃないかと思います。static オブジェクトの扱い、Action などのシリアライズ非対応型など、色々罠があります。ComputeBuffer など UnityEngine のオブジェクトなのにシリアライズ非対応な連中も存在していてなかなか厄介です。
ちゃんと対処するのはめんどくさそうだったので、今回は途中から実行時編集は諦めました。代わりにエディタ上でステージの途中から開始することでイテレーション速度を保つようにしています。
過去に頑張って C++ で同等機能を実装してた身からすると、なんというか予想外に親しみが湧くリアルワールドな世界でした。
今回の冬コミ版の制作を通して、自分のようなオールドタイププログラマーでも Unity とはよろしくやっていけそう、Unity で自分の作りたいゲームは十分作れそう、という確固とした実感を得られました。
C87 / exception reboot
冬コミ参加します。3日目西え25a。
Unity で exception の続編的ゲームを作ろう、という実験も兼ねた挑戦をやっていて、その経過の作品になります。またしても体験版です…。
100 円、いつも通りソースコードも同梱します。また、Direct3D11 が使える GPU が必須になります。
今回もカワノさん (@pocomo) が曲を書いてくださいました。当日は二人で売り子している予定です。
ちなみにソースコードについては、パーティクルエンジンは これ、レンダリングエンジンは これ なので、今回のパッケージに技術的な見どころは特になかったりします…。
パーティクルは CPU 実装ですが、背景のキューブの群れは移動から描画まで GPU で完結するようにしていたりします。
以前の作品 が重すぎた反省から、今回はモバイル GPU でも快適に動くように気を使いながら開発していて、私の Core i7 2.3 Ghz x4 & GetForce GT 750M なノートでも、720p の標準設定であればほぼ 60 FPS で動作するようになっています。(経験的に、M がつく Geforce は、M がつかない同レベル型番の半分以下のパワーです…)
ここ数年ずっとゲームを完成させられずにいるので、来年これを完成させる、というのが当面の死守すべき目標になりそうです。