introdunction to SIMD programming
Unite 2015 Tokyo の講演で詳細を話せなかったのが心残りだったので、大量のオブジェクトの更新処理についてこの場で書いてみます。
主に C++ で、簡単なパーティクルエンジンを作り、それを SIMD を用いて高速化する手順を解説します。
話を簡単にするため、以下の前提を設けます。
・x86 環境のみ考慮
・パーティクルは位置と速度のみを保持
・パーティクル同士の相互衝突は総当たりで計算
総当たりなので超遅いですが、実装は容易で SIMD による恩恵を受けやすく、題材として手頃です。
この記事の中で引用されているソースの元は こちら、ビルド結果 (上のスクリーンショットのデモプログラム) は こちら になります。
相互衝突するパーティクルを実装する場合、お互いの距離を計算し、当たっていたらめり込み具合に応じて押し返す、というのがよくある実装だと思います。まずはそれをストレートに C++ で実装してみます。
const int m_particle_count = 4096; Particle m_particles[m_particle_count]; float m_particle_size = 0.1f; float m_pressure_stiffness = 500.0f; // 押し返し係数 float dt = 1.0f / 60.0f; // 速度を更新。パーティクル同士の押し返し for (int i = 0; i < m_particle_count; ++i) { float3 &pos1 = m_particles[i].position; float3 accel = { 0.0f, 0.0f, 0.0f }; for (int j = 0; j < m_particle_count; ++j) { float3 &pos2 = m_particles[j].position; float3 diff = pos2 - pos1; float dist = length(diff); if (dist > 0.0f) { // dist==0.0 : 自分自身との衝突なので省略 float3 dir = diff / dist; // めり込んでいたら反対方向に加速度を追加 float overlap = std::min<float>(0.0f, dist - m_particle_size*2.0f); float3 a = dir * (overlap * m_pressure_stiffness); accel = accel + a; } } float3 &vel = m_particles[i].velocity; vel = vel + accel * dt; } // 位置を更新。マルチスレッド対応を考慮して速度更新とは分ける for (int i = 0; i < m_particle_count; ++i) { float3 &pos = m_particles[i].position; float3 &vel = m_particles[i].velocity; pos = pos + (vel * dt); }
最適化を有効にしてビルドし、とりあえずシングルスレッドで 4096 個のパーティクルを相互に衝突させてみたところ、所要時間は以下のようになりました。
Plain C++ (ST) : 140.0ms
これがスタートラインです。これをがんばって速くしていきます。
ついでに、適当に重力加速と床とのバウンド処理も入れて Unity で可視化してみるとこうなりました。単純実装ながらなかなかいい感じではないでしょうか。

SIMD
近年では大抵の CPU には 1 命令で複数のデータを同時に計算する命令群が備わっています。これを使うと、例えば 4 つの float の足し算や掛け算を一度に行うことができます。これらは SIMD (Single Instruction Multiple Data) と呼ばれ、CPU プログラミングでシビアに速度を求める場合避けては通れない道になります。
x86 系 CPU には SSE という SIMD 命令群が備わっており、今回の例ではこれを用います。(x86 用なので ARM など他の CPU では動きません。ARM の CPU も大抵は NEON という SIMD 命令群が備わっており、マルチプラットフォーム対応するには個別に実装するなりライブラリを用いるなりする必要があります)
SSE の命令群は intrinsic と呼ばれる関数を用いることで C++ から使うことができます。最初のストレートな C++ 実装を、ベクトル演算を SSE の命令で置き換える形で書きなおすと以下のようになります。
__m128 particle_size2 = _mm_set_ps1(m_particle_size*2.0f); __m128 pressure_stiffness = _mm_set_ps1(m_pressure_stiffness); __m128 dt = _mm_set_ps1(dt_); __m128 zero = _mm_setzero_ps(); // パーティクル同士の押し返し for (int i = 0; i < m_particle_count; ++i) { __m128 pos1 = _mm_load_ps((float*)&m_particles[i].position); __m128 accel = zero; for (int j = 0; j < m_particle_count; ++j) { __m128 pos2 = _mm_load_ps((float*)&m_particles[j].position); __m128 diff = _mm_sub_ps(pos2, pos1); __m128 dist = length(diff); __m128 dir = _mm_div_ps(diff, dist); __m128 overlap = _mm_min_ps(zero, _mm_mul_ps(_mm_sub_ps(dist, particle_size2), pressure_stiffness)); __m128 a = _mm_mul_ps(dir, overlap); accel = _mm_add_ps(accel, select(zero, a, _mm_cmpgt_ps(dist, zero))); } __m128 vel = _mm_load_ps((float*)&m_particles[i].velocity); vel = _mm_add_ps(vel, _mm_mul_ps(accel, dt)); _mm_store_ps((float*)&m_particles[i].velocity, vel); } // 位置を更新 for (int i = 0; i < m_particle_count; ++i) { __m128 pos = _mm_load_ps(m_particles[i].position.v); __m128 vel = _mm_load_ps(m_particles[i].velocity.v); pos = _mm_add_ps(pos, _mm_mul_ps(vel, dt)); _mm_store_ps(m_particles[i].position.v, pos); }
__m128 というのが SSE 用のデータ型で、float が 4 つ格納できる 16 byte のデータになっています。
_mm で始まる関数群が SSE の intrinsic で、大体はこの intrinsic が SSE の命令に直接対応するようになっています。アンダースコアまみれで見にくいですが、関数名に mul とか add とかついているので初見の方でも大体何やってるのかわかるんじゃないかと思います。
注意が必要な点がいくつかあります。
_mm_load_ps() はメモリから SSE のレジスタにデータを移す命令ですが、ロード先のアドレスは 16 byte にアラインされている必要があります。されていない場合クラッシュします。アライン不要の _mm_loadu_ps() というのもありますが、若干速度にペナルティがあるので今回は使っていません。これらは SSE のレジスタからメモリにデータを移す _mm_store_ps() にも同じことが言えます。このため、今回の Particle は position も velocity も 4 次元ベクトル (というか x,y,z + パディング) としています。
SIMD プログラミングでは、例えば x+y+z みたいなベクトルの水平方向の計算をする場合ややこしいことをやる必要があります。こういう処理の典型的な例が内積です。3 次元の内積のストレートな C++ 実装はこうですが、
inline float dot(float3 v1, float3 v2) { return v1.x*v2.x + v1.y*v2.y + v1.z*v2.z; }
SSE だとこうなります。
inline __m128 dot(__m128 v1, __m128 v2) { __m128 d = _mm_mul_ps(v1, v2); // d: x,y,z,w __m128 t = _mm_shuffle_ps(d, d, _MM_SHUFFLE(2, 1, 2, 1)); // t: z,y,z,y d = _mm_add_ss(d, t); // d: xz,... t = _mm_shuffle_ps(t, t, _MM_SHUFFLE(1, 1, 1, 1)); // t: y,y,y,y d = _mm_add_ss(d, t); // d: xyz,... return _mm_shuffle_ps(d, d, _MM_SHUFFLE(0, 0, 0, 0)); // xyz,xyz,xyz,xyz } // 上の SSE 化したパーティクルコードの length() inline __m128 length(__m128 v) { return _mm_sqrt_ps(dot(v,v)); }
_mm_shuffle_ps() が要素を交換する命令で、これを使って要素を入れ替えつつ足しあわせています。見ての通り実装がめんどくさい上に並列性も少なく、コストの高い処理になります。これは SSE に限らず SIMD プログラミングではつきまとう問題で、できるだけ避けた方がいいですが必要な状況も多いです。(SSE 3 で水平方向計算の命令が追加され、SSE 4 では内積を計算するそのものズバリな命令までありますが、今回は一応一般的な SIMD プログラミングという体裁なので使いません)
あとは分岐。SIMD の場合、分岐は両パス計算して結果を選択した方がずっと速いケースが多いです。比較命令 (_mm_cmpgt_ps() = compare greater than など) は結果が真の要素は全ビットが立っている (0xffffffff) ので、これを使ってビット演算で結果を選択します。
inline __m128 select(__m128 v1, __m128 v2, __m128 mask) { __m128 t1 = _mm_andnot_ps(mask, v1); __m128 t2 = _mm_and_ps(v2, mask); return _mm_or_ps(t1, t2); }
例えば v1 が {0,1,2,3}、v2 が {4,5,6,7} で mask が {0, 0xffffffff, 0xffffffff, 0} の場合、この select() は {0,5,6,3} を返します。上の SSE 化したパーティクルのコードもこれで結果を選択しています。
SSE 化したソースをビルドして最初のケースと同条件 4096 パーティクル シングルスレッドで動かしてみました。
Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms (new!)
実に 3 倍も速くなりました。
SoA
SIMD 化により大きく速くはなりましたが、上記の SSE 化したコードには色々無駄があります。position も velocity も実際には x,y,z の 3 要素しか使われていません。なので SIMD 演算の際 w 要素部分の計算は完全に無駄になっており、計算リソースを 25% も無駄にしていることになります。また、先述の dot() / length() の中の並べ替えも大きなロスになります。
これらを解決する手法として、SoA (Structure of Arrays) と呼ばれるデータ構造があります。
C++ で多数のオブジェクトを扱う場合、各オブジェクトに付随するデータを class や struct にまとめて配列にする、というのが一般的だと思われます。
struct Particle { float pos_x, pos_y, pos_z; float vel_x, vel_y, vel_z; }; Particle particles[particle_count];
このようなデータの持ち方は AoS (Array of Structures) と呼ばれることもあります。SoA はこれとは逆で、データの各要素を配列にする、というデータの持ち方になります。
float pos_x[particle_count]; float pos_y[particle_count]; float pos_z[particle_count]; float vel_x[particle_count]; float vel_y[particle_count]; float vel_z[particle_count];
直感的ではないデータの持ち方ですが、SIMD プログラミングではこれは大きなメリットがあります。4 つのオブジェクトを同時に計算できるようになるのです。先ほどの続きで、内積を例に考えてみましょう。SoA なデータに対して SSE で内積と距離を計算する場合、こうなります。
inline __m128 soa_dot(__m128 x1, __m128 y1, __m128 z1, __m128 x2, __m128 y2, __m128 z2) { __m128 tx = _mm_mul_ps(x1, x2); __m128 ty = _mm_mul_ps(y1, y2); __m128 tz = _mm_mul_ps(z1, z2); return _mm_add_ps(_mm_add_ps(tx, ty), tz); } inline __m128 soa_length(__m128 x, __m128 y, __m128 z) { return _mm_sqrt_ps(soa_dot(x,y,z, x,y,z)); }
やってることはストレートな C++ 実装と同じですが、4 つのベクトルを同時に計算するようになっています。前述のベタな SSE 化の dot() と違い、shuffle は必要ないですし w 要素の計算が無駄になることもありません。ベタな SSE 化はベクトル演算それぞれを SSE 命令に置き換えていましたが、SoA の場合 4 つのパーティクルを同時に行うことで並列化するイメージです。
SoA にはスケーラビリティの面でも大きなメリットがあります。近年の x86 CPU には AVX という SIMD 命令群が追加されており、これを使うと 8 つの float を同時に計算できます。しかし 8 次元ベクトルなんてゲーム開発ではまず出てこないので、単純にベクトル演算を SIMD 命令に置き換えるアプローチではこれを活かすのは難しいです。一方、SoA であれば 8 オブジェクト並列に計算することで最大限に恩恵を受けることができますし、将来 16 並列や 32 並列 SIMD が出てきたとしても簡単に対応できます。
実際にパーティクルを SoA 化して計算してみます。まずパーティクルデータを SoA 化する必要があります。AoS <-> SoA の転置を行うには、SSE では以下のような処理を行います。
union soafloat4 { struct { __m128 x, y, z, w; }; __m128 v[4]; }; inline soafloat4 soa_transpose(__m128 v0, __m128 v1, __m128 v2, __m128 v3) { __m128 r1 = _mm_unpacklo_ps(v0, v1); __m128 r2 = _mm_unpacklo_ps(v2, v3); __m128 r3 = _mm_unpackhi_ps(v0, v1); __m128 r4 = _mm_unpackhi_ps(v2, v3); soafloat4 r = { _mm_shuffle_ps(r1, r2, _MM_SHUFFLE(1, 0, 1, 0)), // {v0.x, v1.x, v2.x, v3.x} _mm_shuffle_ps(r1, r2, _MM_SHUFFLE(3, 2, 3, 2)), // {v0.y, v1.y, v2.y, v3.y} _mm_shuffle_ps(r3, r4, _MM_SHUFFLE(1, 0, 1, 0)), // {v0.z, v1.z, v2.z, v3.z} _mm_shuffle_ps(r3, r4, _MM_SHUFFLE(3, 2, 3, 2)) };// {v0.w, v1.w, v2.w, v3.w} return r; }
これを用いてパーティクルを SoA 化し、衝突計算を行います。
__m128 particle_size2 = _mm_set_ps1(m_particle_size*2.0f); __m128 pressure_stiffness = _mm_set_ps1(m_pressure_stiffness); __m128 dt = _mm_set_ps1(dt_); __m128 zero = _mm_setzero_ps(); // パーティクル同士の押し返し for (int i = 0; i < m_particle_count; ++i) { __m128 pos1x = _mm_set_ps1(m_soa.pos_x[i]); __m128 pos1y = _mm_set_ps1(m_soa.pos_y[i]); __m128 pos1z = _mm_set_ps1(m_soa.pos_z[i]); __m128 accelx = zero; __m128 accely = zero; __m128 accelz = zero; for (int j = 0; j < m_particle_count; j += 4) { __m128 pos2x = _mm_load_ps(&m_soa.pos_x[j]); __m128 pos2y = _mm_load_ps(&m_soa.pos_y[j]); __m128 pos2z = _mm_load_ps(&m_soa.pos_z[j]); __m128 diffx = _mm_sub_ps(pos2x, pos1x); __m128 diffy = _mm_sub_ps(pos2y, pos1y); __m128 diffz = _mm_sub_ps(pos2z, pos1z); __m128 dist = soa_length(diffx, diffy, diffz); __m128 dirx = _mm_div_ps(diffx, dist); __m128 diry = _mm_div_ps(diffy, dist); __m128 dirz = _mm_div_ps(diffz, dist); __m128 overlap = _mm_min_ps(zero, _mm_mul_ps(_mm_sub_ps(dist, particle_size2), pressure_stiffness)); __m128 ax = _mm_mul_ps(dirx, overlap); __m128 ay = _mm_mul_ps(diry, overlap); __m128 az = _mm_mul_ps(dirz, overlap); __m128 gt = _mm_cmpgt_ps(dist, zero); accelx = _mm_add_ps(accelx, select(zero, ax, gt)); accely = _mm_add_ps(accely, select(zero, ay, gt)); accelz = _mm_add_ps(accelz, select(zero, az, gt)); } __m128 velx = _mm_set_ss(m_soa.vel_x[i]); __m128 vely = _mm_set_ss(m_soa.vel_y[i]); __m128 velz = _mm_set_ss(m_soa.vel_z[i]); velx = _mm_add_ss(velx, _mm_mul_ss(reduce_add(accelx), dt)); vely = _mm_add_ss(vely, _mm_mul_ss(reduce_add(accely), dt)); velz = _mm_add_ss(velz, _mm_mul_ss(reduce_add(accelz), dt)); _mm_store_ss(&m_soa.vel_x[i], velx); _mm_store_ss(&m_soa.vel_y[i], vely); _mm_store_ss(&m_soa.vel_z[i], velz); } // 位置を更新 for (int i = 0; i < m_particle_count; i += 4) { __m128 posx = _mm_load_ps(&m_soa.pos_x[i]); __m128 posy = _mm_load_ps(&m_soa.pos_y[i]); __m128 posz = _mm_load_ps(&m_soa.pos_z[i]); __m128 velx = _mm_load_ps(&m_soa.vel_x[i]); __m128 vely = _mm_load_ps(&m_soa.vel_y[i]); __m128 velz = _mm_load_ps(&m_soa.vel_z[i]); posx = _mm_add_ps(posx, _mm_mul_ps(velx, dt)); posy = _mm_add_ps(posy, _mm_mul_ps(vely, dt)); posz = _mm_add_ps(posz, _mm_mul_ps(velz, dt)); _mm_store_ps(&m_soa.pos_x[i], posx); _mm_store_ps(&m_soa.pos_y[i], posy); _mm_store_ps(&m_soa.pos_z[i], posz); }
すっごく冗長になってしまいましたが、__m128 を float に置換してみると意味は明瞭になるんじゃないかと思います。
速度更新フェーズの内側のループで 4 パーティクルとの距離計算を同時に行い、最後に 4 つの結果を reduce add して統合しています。recuce_add() の中身はそのまんま __m128 の中の 4 要素を足しあわせているだけです。
inline __m128 reduce_add(__m128 v1) { __m128 v2 = _mm_movehl_ps(v1, v1); // z,w,z,w v1 = _mm_add_ps(v1, v2); // xz,yw,zz,ww v2 = _mm_shuffle_ps(v1, v1, _MM_SHUFFLE(2, 2, 2, 2)); // yw, yw, yw, yw v1 = _mm_add_ss(v1, v2); // xzyw, ... return v1; }
実行結果。
Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms (new!)
ベタな SSE 化からさらに倍以上速くなりました。Update のたびに毎回 SoA に並べ替えて計算して AoS に戻しているのでトータル処理量は増えているはずですが、それでもこれだけ効果があります。
ISPC
先に少し触れたように、近年の x86 CPU には AVX と呼ばれる命令群が備わっており、これを使うと 8 つの float を同時に計算できます。理想的なケースでは本当に SSE のほぼ倍の速度が出せます。ぜひ使いたいところです。
しかし、AVX が使える CPU は Intel Sandy Bridge (2011) 以降であり、まだ十分に普及しているとは言えません。なので AVX を使うにしても SSE 実装と AVX 実装両方を用意して実行時に使える方を選ぶのが実用的なやり方になります。
とはいえ、両方実装するのは面倒です。今回の例くらい単純なケースでは SSE, AVX 両方実装するのも大したコストではありませんが、ここでは紹介もかねて ISPC を使ってラクをしてみます。
http://ispc.github.io/
ISPC は SIMD に特化したプログラミング言語です。
SIMD の各レーンを実行単位と見立てた記述をするようになっています。ISPC で記述してコンパイルすると、SSE, AVX, ARM (NEON) それぞれに最適化されたコードを出力することができます。SSE と AVX に関しては、両方の実装を用意して実行時に使える方を選ぶのを自動的にやってくれます。コンパイル結果は .obj と .h として出力され、簡単に C/C++ のプログラムにリンクできます。Windows はもちろん、Mac、Linux、PS4 向けにもクロスコンパイルできます。
詳しい解説はこちらに委ねますが、ここまで読んでくれた方であれば、最初のストレートな C++ 実装に近い記述で、上の SIMD & SoA と同じ内容にコンパイルできる言語、という説明がわかりやすいんじゃないかと思います。
SoA <-> AoS 化は C++ 側で行い、それを ISPC で書いたカーネルに渡して処理します。ISPC のコードは以下のようになります。
// パーティクル同士の押し返し for(uniform int i=0; i<particle_count; ++i) { uniform float3 pos1 = {pos_x[i], pos_y[i], pos_z[i] }; float3 accel = {0.0f, 0.0f, 0.0f}; foreach(j=0 ... particle_count) { float3 pos2 = {pos_x[j], pos_y[j], pos_z[j] }; float3 diff = pos2 - pos1; float dist = length(diff); float3 dir = diff / dist; float3 a = dir * (min(0.0f, dist-(particle_size*2.0f)) * pressure_stiffness); accel = accel + (a * select(dist > 0.0f, 1.0f, 0.0f)); } uniform float3 vel = {vel_x[i], vel_y[i], vel_z[i] }; vel = vel + reduce_add(accel) * dt; vel_x[i] = vel.x; vel_y[i] = vel.y; vel_z[i] = vel.z; } // 位置を更新 for(i=0 ... particle_count) { float3 pos = {pos_x[i], pos_y[i], pos_z[i] }; float3 vel = {vel_x[i], vel_y[i], vel_z[i] }; pos = pos + (vel * dt); pos_x[i] = pos.x; pos_y[i] = pos.y; pos_z[i] = pos.z; }
実にすっきりしました。これを SSE をターゲットにしてコンパイルすると上の SoA & SSE のコードとほぼ同じ内容のバイナリになりますし、AVX をターゲットにすれば AVX 実装のできあがりです。
AVX をターゲットにする際の注意点として、SSE が 16 byte align が必要だったように、AVX だと 32 byte align が必要になります。なので今回は最初からパーティクルは 32 byte align でメモリを確保しています。
これをビルドして実行してみます。
Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms ISPC (ST) : 12.3ms (new!)
さらに 1.6 倍も速くなりました。処理内容は SSE & SoA と同じなので、このスピードアップは AVX 化によるものと言えます。
ISPC の便利さは SIMD プログラミングを長いことやってる人ほど身にしみるんじゃないかと思います。一頃に比べるとコンパイラのバグリーな動作は少なくなり、対応プラットフォームも増えたので、実戦投入も検討に値するレベルになってきたんじゃないでしょうか。
余談ですが、ISPC の "SIMD の各レーンを実行単位に見立てる" という考え方はシェーダプログラミングにも当てはまり、近年の NVIDIA や AMD の GPU ではシェーダプログラムは 32 の SIMD レーン (NVIDIA が "Warp"、AMD が "Wavefront" と呼んでるもの) それぞれで並列に実行されるようになっています。なので、ISPC はシェーダプログラミングのパラダイムを CPU の SIMD で実装したもの、とも言えると思います。
そんなわけで、色々頑張った結果最初のストレートな C++ 実装から 10 倍くらい速くなりました。これをマルチスレッド化までやると最近の Core i7 の比較的いいやつだと 8192 パーティクルが 60 FPS で動くようです。(= 67108864 回の距離計算が 16ms 以内で終わる!)
Unite 2015 Tokyo でデモした MassParticle はハッシュグリッド法で近隣パーティクルのみと衝突計算する最適化を入れていますが、衝突計算自体は今回の例と全く同じになっています。
解説はここまでです。記事中のソースは簡略化しているので、より詳細に実装を知りたい場合 github に上がってるソースを見ることをおすすめします。SIMD はアルゴリズムが単純でメモリアクセスが少ないケースで特に効果的です。弾幕やパーティクルなど、単純なオブジェクトの大量処理は SIMD に向いた問題なので、数出したい方は足を踏み入れてみるといいでしょう。
あと、もっと速くする方法がありましたらご一報ください。
C#
おまけ。最初のストレートな C++ 実装を C# で再実装してみました。
ソース
実行結果:
Plain C# (ST) : 1196.1ms (new!) Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms ISPC (ST) : 12.3ms
Unity でスクリプトに速度を求めるならプラグイン書いた方がいい、というのがどういうことなのかよくわかると思います。
一応 C# を弁護しておくと、こういう数値計算の類は C# が苦手な処理の最たるものであり、ここまで差が出るケースはレアなはずです。また、C# でもバックエンドが最新の .Net だったりするともうちょっとマシな結果になると思います。
あと、元の C++ 実装を最適化 無効 でビルドすると C# の方が速くなりました。この結果を見ると IL2CPP のアプローチは意外と合理的なんじゃないかと思えてきます。
Compute Shader
おまけ 2。Compute Shader でも実装してみました。
ソース
実行結果:
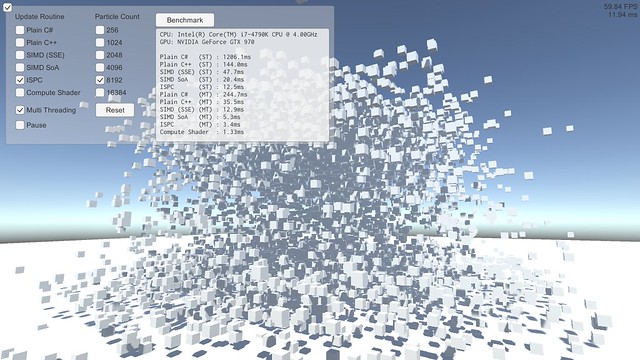
CPU: Intel(R) Core(TM) i7-4790K CPU @ 4.00GHz GPU: NVIDIA GeForce GTX 970 Plain C# (ST) : 1196.1ms Plain C++ (ST) : 140.0ms SIMD (SSE) (ST) : 46.6ms SIMD SoA (ST) : 20.0ms ISPC (ST) : 12.3ms Plain C# (MT) : 224.7ms Plain C++ (MT) : 33.4ms SIMD (SSE) (MT) : 12.1ms SIMD SoA (MT) : 5.1ms ISPC (MT) : 3.2ms Compute Shader : 1.45ms (new!)
Compute Shader と比較する場合、CPU 側もマルチスレッド化していないとフェアじゃないのでそうしています。Compute Shader の処理時間は、Dispatch() を呼ぶ直前から計算結果を CPU 側に書き戻すまで、で測定しています。(Dispatch() から制御が戻った時点では実際の処理はまだ終わってないので) なので CPU 側にデータを移す時間分 Compute Shader に不利に働く条件になっているはずですが、これだけの性能が出ます。NVIDIA NSight で純粋な処理時間も見てみたところ、大体 1.1ms くらいという感じでした。

ゲームでは GPU は大抵レンダリングで忙しいので GPGPU は使いどころが難しいですが、グラフィックはそこそこに留めてこの計算パワーを活かしたゲームデザインを模索してみるのも面白いかもしれません。